New Zealand startup Zenno Astronautics has completed the first orbital test of its "Supertorquer," a shoebox-sized superconducting magnet system that uses solar power and Earth's magnetic field to help control a satellite without fuel. The company says the technology could eventually support fuel-free satellite maneuvers, docking, deep-space trajectory changes, and even magnetic radiation shielding for astronauts. Space Magazine reports: The tests began shortly after Mira's launch in November last year aboard the SpaceX Transporter 12 mission and saw the shoebox-size device perform with flying colors, Zenno Astronautics CEO and founder Max Arshavsky, told Space.com. "It's a technology that allows a spacecraft to not tumble violently in space and point in the right direction," Arshavsky said. "The unit has multiple super-conducting magnets that are positioned in different axes. When we power up the magnets, they generate a magnetic field, which interacts with Earth's magnetic field, and because we can control the magnetic field on the satellite, we can control the way in which it turns with respect to Earth."
Superconducting magnets are made of coils of superconducting wire that have zero electrical resistance and can therefore conduct much larger currents than normal wires. That larger current translates into a greater magnetic force. There is, however, a catch: Superconducting materials need to be cooled to extremely low temperatures to gain their wonder properties. [...] The unit housing the superconducting magnets is wrapped in layers of insulation and fitted with a heat pump that removes all the excess heat from the system. Every time the satellite needs a push, the superconducting coils power up, drawing energy from a battery charged by the satellite's solar panels.
"It's converting solar energy straight into useful work," Arshavsky said. "Energy is the one thing that is abundant in space, and you can use it to energize the magnet to create a magnetic acceleration device. It gives you acceleration without fuel." In the future, Zenno Astronautics plans to launch larger systems that could enable spacecraft to dock in space or conduct close proximity operations using just the power of their solar-powered superconducting magnets. Arshavsky envisions powerful magnets that could, in the future, propel spacecraft on missions to the moon and Mars using only solar power.
sounds cool but I dunno if there's anything real there.
I searched on arxiv and google scholar for any recent publications about this, and didn't find any using the keywords that are here and in the Space Magazine article, or any similar terms I tried.
The Zenno leadership listed on their website have some scientific publications but nothing relevant to this that I spotted. For instance, one of Wieczorek's recent publications was "Classifying seizure generation mechanisms: A critical transitions framework", while Arshavsky himself doesn't have anything coming up on Scholar except "Enabling a Multi-National Commercial Destination in Space: The Port" which is a sales pitch that was delivered at something called AIAA SCITECH 2022 Forum.
Magnetic fields are quite feeble -- wikipedia describes the surface flux density relative to a "strong fridge magnet" (not even a rare earth magnet) -- and it's 150 to 450 times less intense. Surprisingly, though, it diminishes relatively little from earth surface to LEO; the dipole model suggests it would be 70% as strong at 800 miles above the earth's surface, only 12.5% further from the earth's center than the surface.
However, it's not the intensity that matters, but the magnetic pressure. Magnetic pressure is generated by the gradient in magnetic field strength. The gradient of the earth's magnetic field in LEO is quite tiny! You wouldn't worry too much about taking a kitchen magnet on a maglev train, because its gradient is so small a meter or two away where the maglev is doing its thing! But that gradient would be much stronger than the one they're proposing to use here.
My gut is telling me this probably generates quite a tiny tiny amount of thrust and I really wish there was some scientific paper adjacent to these folks to show that it's even plausible that it could be plausibly useful for the simplest proposed purpose.
"Magnetorquers" have been in use for LEO station-keeping for decades. But they only work in LEO because only there is the Earth's magnetic field strong enough. It's _possible_ that this new tech enables use in higher orbits, and that really would be a breakthrough, but I don't buy its being workable in deep space.
Right. I don't properly understand why myself, but magnetorquers cannot generate forces on the center of mass of the satellite, only torques. I doubt the superconducting version is any different.
We are thrilled to welcome Kattni as the next Co-Chair and future Chair of PyCon US! You may already know Kattni from her work on CircuitPython and BeeWare, as a conference speaker, and as the Conference Chair of PyOhio since 2024. We are truly excited for what she will bring to PyCon US and its community over the next four years, and we can't wait to share that with you. In her own words:
Hello, all! I'm Kattni, and I've been a Python community organiser for nearly a decade. I'm grateful to have spent the last three years as the PyOhio conference chair. PyOhio 2017 was the first technical conference I attended, and to now be able to guide the community that accepted me so openly as a new programmer has been a wonderful experience. I was simultaneously welcomed into the CircuitPython community, and I was able to spend the next six years returning the favor, building that community from the ground up. In 2024, I found a welcoming, supportive home in the BeeWare community, and I have since been working to create a space where others can find the same. I am greatly looking forward to the opportunity to bring my experience and energy to PyCon US.
Everyone has different reasons for attending PyCon US; the event has a wide range of things to offer. For me, it's about the people -- seeing old friends and making new ones is by far my favorite part of the conference. I want to focus on helping the PyCon US community grow, to further cultivate the myriad perspectives, and increase the opportunities for everyone involved to have their own amazing and memorable experiences. When it comes down to it, PyCon US happens at all because of those who participate. It wouldn't exist without, at a very minimum, those who: organise it, run it, volunteer both before and during, submit to the CFP, speak, teach tutorials, present posters, sponsor, and attend.
I hope you'll join us next year in Long Beach, as I begin my journey helping make PyCon US a wonderful event. I'm incredibly excited to be working alongside Jon, and the rest of the staff, organisers, and volunteers, through the next four years. I'm looking forward to seeing everyone next year!
We'll have more news to share about PyCon US 2027 in the coming months. Stay tuned to the blog and newsletter for updates. We look forward to welcoming you back to Long Beach next May 12 - 18.
In the mid-2010s, Time’s pronouncement that America had reached the transgender tipping point overshadowed another startling edict from Salon a few months later: Ass was the new pussy.
Licking it. Suckling it. Introducing it to a curious finger. Dicking it down with fleshy and artificial phalluses. The world had caught up to Mozart, who, in 1782, penned “Leck mich im Arsch,” translated from German as “Lick me in the ass.” He probably meant kiss my ass, but who are we to presume the inner workings of a genius who loved poop and fart jokes.
Though the practice of darting fast and deep between the cheeks is indeterminably old, psychiatrist Richard von Krafft-Ebing didn’t coin the term anilingus until 1886. The Romans defined cunnilingus and fellatio for us centuries earlier.
Salon’s 2015 ass supremacy proclamation quoted porn star Asa Akira. She was right. Culturally, by then, everyone was talking and singing about tonguing ass, even the straights. Nicki Minaj sang about a guy tossing her salad in “Anaconda” around the same time disgraced NBC Nightly News anchor Brian Williams watched his daughter Allison Williams act out anilingus on the season four premiere of Girls. A father’s dream.
How times change. A month after his daughter got rimmed on TV, NBC suspended Williams because he told a BS story about Iraq, claiming that he’d been on a helicopter that was forced to land when it took rocket-propelled grenade fire. It never happened. Minaj has moved on from ass to shit—she’s gone MAGA.
Some of those who helped move ass eating into pop culture may be gone from our hearts, but rimming remains evermore. Still, I worry. Whenever a sexual practice hits the mainstream, the discussion tends to focus on licking invisible, cultural barriers and not speaking of the actual, physical barriers and practices that make sex safe. I get why. Taboos are more fun to talk about than STIs, or giardia, one of the microscopic parasites one can ingest when rambling south of the taint.
The two primary risks are sexually transmitted infections and bacteria. Australian studies have shown that men who have sex with men (MSM) were having steadily more oral-to-anal sex between the 1980s and early 2000s. An Australian study from 2016 found that among 1,312 MSM, 70.5 percent had received anilingus. The authors of the study concluded that the use of saliva during sex—from rimming and as lubricant for anal sex and fingering—“may play a key role in gonorrhea transmission in MSM.” Data from another Australian study in 2022 suggested that both kissing and rimming were “important” practices in gonorrhea transmission. We know that bacteria like shigella and campylobactor can also transmit this way.
In regard to the sex pests we’re all more familiar with—gonorrhea, syphilis, hepatitis, Mpox, and so on—anilingus is not unusually risky. But there’s risk. It’s sex.
Gonorrhea can pass from the throat to the asshole, no problem. In its early stage, syphilis spots can bloom on the mouth and tongue. Mpox, formerly known as monkeypox, is transferred by skin-to-skin contact if lesions are present. You can also catch HPV, chlamydia, herpes, hepatitis A, and hepatitis B (a lower risk) through anilingus. However, your chance of HIV infection from oral-anal contact is basically zero in the absence of bleeding gums or open sores.
If I ever had the MAHA crowd, by now I’ve lost them, so please get vaccinated against common STIs if you have the means. It’s an easy way to help yourself and your community.
Concerning heterosexuals, yet another Australian study found men were far more likely (25.5 percent) to have rimmed their partners than women (9.3 percent). Whether this has to do with straight men washing or not washing their ass cracks in the shower, I cannot speculate.
I’m not saying the data should dissuade you or anyone else from rimming. I simply believe information is both a sword and a shield. Dr. Chase Cannon, a provider at the county’s Sexual Health Clinic at Harborview, whom I called last month, didn’t want to rain on anyone’s parade either.
“Folks can have their pleasure as long as they’re being mindful,” he says.
Here’s a practical question before you go down: Hey, [partner X], are you feeling well? If the answer is “no,” give rimming a pass, at least for the night.
Joshua Lumsden, a physician assistant certified at the queer-focused clinic Capitol Hill Medical, concurred. If a partner is vomiting or having diarrhea, it’s “not a good time to fill your mouth with joy.”
There’s always the risk that partner X is sick and does not know it. Asymptomatic transmission is possible. Dr. Cannon knows this might not be the “most popular” suggestion, but he says consider using a barrier like a dental dam, or taking a regular condom, slicing it lengthwise, and laying down that raincoat like a picnic blanket between two hills. Consider a dab of lube for anal comfort.
A gentle, external wash of the anus with soap and lukewarm tap water can also reduce the chance of a bacterial infection. The poop-sensitive among us who cannot tolerate the thought of another human being discovering shit in their ass may be tempted to reach for the douche. Drop it!
Dr. Cannon says research shows douching can increase the risk of certain infections because it wears down the lining of the rectum by creating microtears and bringing immune cells to the surface. But if you must power wash your hole, opt for lukewarm tap water. Commercially available enema solutions are too harsh. As are hot water and high pressure.
And if you are using soap on the outside of your hole, avoid anything scented or dyed, as they can also carry an STI risk from irritating the rectal lining, Lumsden added. “Probably, more practically, you just don’t want an irritated butthole.”
Here are a few more wise words: While you’re washing your ass, wash your hands, and consider the order in which you do those two things. Following a sexual PEMDAS is generally a good idea. (Please Excuse My Dear Ass, Sexually.)
It is no easy task in the heat of the moment. If you’ll allow me to speak directly to your lizard brain: ass last. Pole before hole. Pink before stink. Alternating between the ass and the genitals is like inviting a UTI into your living room and offering it a tall glass of anything but cranberry juice cocktail.
If you want to rim a partner and are unsure their hygiene is up to snuff—either because you don’t know them or know them all too well—Lumsden suggests you incorporate showering into foreplay. That way, nobody gets their feelings hurt or an unpleasant, surprising flavor with a sickening after-effect.
But ass eating is not all biological. It’s a matter of the heart as well. Asking to lick someone’s ass, or asking them to lick yours, is vulnerable.
Zoey Watson-Hanson, a LICSW in Seattle, talked about how it may be easier for people seeking casual and spontaneous sex on Tinder or Feeld to ask for what they want than it is for people in established partnerships with long-term partners. It depends on how comfortable they’ve been sharing their sexual interests in the past. Either way, “what you got to do is just come right out and say it,” she says—preferably not while you’re in the middle of sex, when someone might feel more pressured.
Just be normal about it: Pick a casual setting, during a non-aroused conversation, and deliver that ask as an ask, not an ultimatum. Emphasize pleasure and consent, and let your partner ask questions. Eating ass may be simpler for you than for a germaphobe or reformed fundamentalist who connects a “dirty” act to moral impurity. In other words, you gotta go deep to get deep.
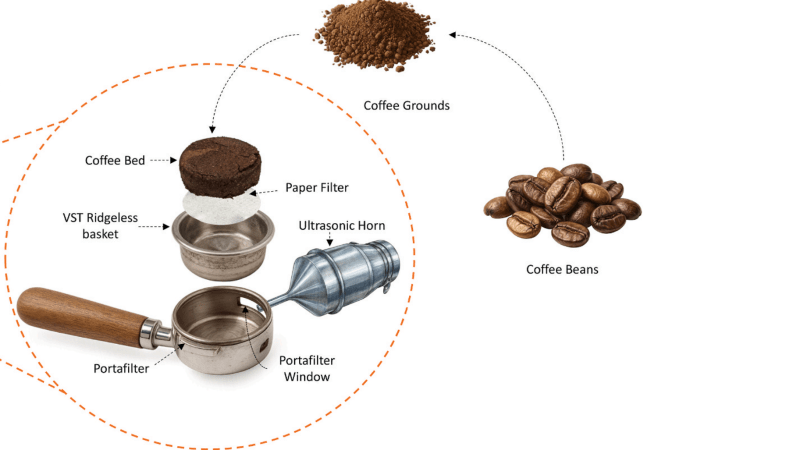
There are as almost as many kinds of coffee as there are of coffee drinkers, with each method for preparing the beverage appealing to a different kind of palate: moka pots, filter coffee, pour-over coffee, French presses, cold brews, espresso, and more produce their own unique flavours by extracting different compounds from the grounds to different degrees. Now, a new method has joined the throng: ultrasonic-assisted extraction, which can produce even an espresso at room temperature.
Espresso is normally made by forcing hot water through tightly-packed, finely-ground coffee beans, quickly producing a concentrated extraction. Its one of the hardest kinds of coffee to consistently make well, since the outcome is influenced by everything from grind size and packing density to temperature, pressure, and more. Ultrasonic agitation helps here by creating cavitation bubbles, which form shock waves as they collapse, breaking open the bean structure and producing small, strong jets of water. The experimental apparatus was built into a modified espresso machine. An ultrasonic transducer delivers vibrations to the basket containing the room-temperature slurry of coffee grounds for two or three minutes.
To quantify the results, the researchers analysed total dissolved solids, extraction yield, pH, colour, volatile components, and caffeine and chlorogenic acid contents. By varying ultrasonic power and grind size, the extraction yield and dissolved solids could be adjusted to closely match traditional espresso or cold-brew coffee. The other metrics had no significant differences, and a survey of 100 coffee drinkers found no preference between this and traditional espresso. When the drinkers tried the cold-brew coffees, they preferred the version made with ultrasonic assistance. The experiment succeeded in its goal of reducing energy consumption: the ultrasonic-assisted coffee took about a quarter as much power to make.